Recently I started looking at reworking the recommendation feature in the Confetti Compose Multiplatform sample (which uses Apollo Kotlin to consume a GraphQL API serving data for various conferences). The new implementation uses a Koog AIAgent with a ToolRegistry that includes session and speaker tools, giving the LLM on-demand access to the conference data it needs.
That works well for direct lookups but is less useful for topic-style queries. Asking “what AI talks are on?” depends on the model guessing the exact word that will appear in the title or description, and any session that uses different wording (e.g. “agentic”, “LLMs”, “embeddings”) gets missed. In this article we’ll look at adding semantic search over the conference sessions using Koog’s embeddings and RAG modules, so that the agent can find related talks even when the wording doesn’t match.
A quick word on embeddings and RAG
An embedding is a numeric representation of a piece of text (a list of floating point numbers, often referred to as a vector) produced by a model that’s been trained so that pieces of text with similar meaning end up close together in that vector space. Two strings that mean roughly the same thing will produce vectors with a high cosine similarity, even if they share no words in common. This is what allows us to take a query like “AI” and surface a session titled “Building agents with LLMs” without ever doing a string match.
RAG (Retrieval-Augmented Generation) is the broader pattern of giving an LLM access to data it wasn’t trained on by retrieving relevant pieces from your own data at query time and feeding them into the prompt (or, in the agent case, returning them from a tool call). The retrieval step is typically powered by embeddings: you embed every document up front, store the vectors, then at query time embed the user’s question and return the documents whose vectors are closest. In our case the “documents” are conference sessions and the retrieval happens through a tool the agent can choose to call.
Implementation
We first add the relevant dependencies (the embeddings base module along with the RAG base and vector storage modules). We’re also adding Okio which we’ll use later to back a multiplatform on-disk cache for the embeddings.
libs.version.toml
1
2
3
koog-embeddings-base = { module = "ai.koog:embeddings-base", version.ref = "koogAgents" }
koog-rag-base = { module = "ai.koog:rag-base", version.ref = "koogRag" }
koog-rag-vector = { module = "ai.koog:rag-vector", version.ref = "koogRag" }
build.gradle.kts
1
2
3
4
implementation(libs.koog.embeddings.base)
implementation(libs.koog.rag.base)
implementation(libs.koog.rag.vector)
implementation(libs.okio)
Koog’s Embedder interface is what maps a piece of text to a Vector (the numeric representation used for similarity comparisons). We’re using Gemini both for the LLM driving the agent and for the embedding model, so we wrap Koog’s LLMEmbeddingProviderAPI (which GoogleLLMClient implements) in a small ApiEmbedder that conforms to the Embedder interface.
1
2
3
4
5
6
7
8
class ApiEmbedder(
private val provider: LLMEmbeddingProviderAPI,
private val model: LLModel,
) : Embedder {
override suspend fun embed(text: String): Vector = Vector(provider.embed(text, model))
override fun diff(embedding1: Vector, embedding2: Vector): Double =
1.0 - embedding1.cosineSimilarity(embedding2)
}
Indexing the sessions
Next up we define a SessionEmbeddingIndex that pulls all sessions for the current conference from the Apollo cache, embeds them, and stores them in a Koog VectorStorageBackend. We keep two separate indexes, one over titles and one over the combined title + description, and at query time take the better of the two scores per session. This stops a passing keyword in a long description from outranking a session whose title is actually about the topic.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
class SessionEmbeddingIndex(
private val repository: ConfettiRepository,
private val conference: String,
private val embedder: Embedder,
cache: EmbeddingCache?,
) {
data class Scored(val session: SessionDetails, val score: Double)
private val titleStorage: VectorStorageBackend<String> = backend(cache?.root, "title")
private val docStorage: VectorStorageBackend<String> = backend(cache?.root, "doc")
suspend fun search(query: String, topK: Int): List<Scored> {
ensureBuilt()
val queryVector = embedder.embed(query)
val merged = mutableMapOf<String, Double>()
titleStorage.allDocumentsWithPayload().toList().forEach { (id, v) ->
merged[id] = v.cosineSimilarity(queryVector)
}
docStorage.allDocumentsWithPayload().toList().forEach { (id, v) ->
val s = v.cosineSimilarity(queryVector)
merged[id] = maxOf(merged[id] ?: Double.NEGATIVE_INFINITY, s)
}
val sessions = repository.allSessions(conference).associateBy { it.id }
return merged.entries
.sortedByDescending { it.value }
.take(topK.coerceAtLeast(1))
.mapNotNull { (id, score) -> sessions[id]?.let { Scored(it, score) } }
}
}
ensureBuilt() is called on the first search. It walks the session list, embeds anything that isn’t already in the backing storage and writes the vectors out. If the on-disk cache is present, subsequent runs only re-embed sessions that are new since the last build. This matters because embedding every session of every conference on every cold start would be slow and would also use up the Gemini quota.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
private suspend fun ensureBuilt() {
if (built) return
mutex.withLock {
if (built) return
val sessions = repository.allSessions(conference)
val cachedIds = titleStorage.allDocuments().toList().toSet()
for (session in sessions.filter { it.id !in cachedIds }) {
val titleVec = embedder.embed(session.title)
titleStorage.store(session.id, titleVec)
val docText = session.sessionDescription
?.takeIf { it.isNotBlank() }
?.let { "${session.title}\n$it" }
?: session.title
val docVec = embedder.embed(docText)
docStorage.store(session.id, docVec)
}
built = true
}
}
Persistent storage with Okio
Koog provides an InMemoryVectorStorageBackend along with a FileVectorStorageBackend that reads and writes vectors through a FileSystemProvider and a DocumentProvider. The FileSystemProvider interface is java.nio.Path based, so to use it from commonMain we add a small Okio-backed implementation.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
class OkioFileSystemProvider(
private val fs: FileSystem,
) : FileSystemProvider.ReadWrite<Path> {
override fun toAbsolutePathString(path: Path): String = path.normalized().toString()
override fun joinPath(base: Path, vararg parts: String): Path =
parts.fold(base) { acc, part -> acc.resolve(part.toPath()) }.normalized()
override suspend fun list(directory: Path): List<Path> =
fs.list(directory).sortedBy { it.name }
// ... read/write/metadata/etc backed by okio.FileSystem
}
ConferenceAgentProvider takes the Embedder and an optional EmbeddingCache as constructor parameters, and these are provided per platform through the project’s Koin DI modules (alongside the existing LLModel and PromptExecutor bindings).
1
2
3
4
5
6
7
8
9
10
data class EmbeddingCache(val fs: okio.FileSystem, val root: okio.Path)
class ConferenceAgentProvider(
private val repository: ConfettiRepository,
private val conference: String,
private val llModel: LLModel,
private val promptExecutor: PromptExecutor,
private val embedder: Embedder,
private val embeddingCache: EmbeddingCache?,
) : AgentProvider { /* ... */ }
On Android we use the app’s cacheDir, on iOS the NSCachesDirectory, on the JVM ~/.cache/confetti-embeddings, and on wasmJs we don’t register an EmbeddingCache at all (which causes SessionEmbeddingIndex to fall back to the in-memory backend).
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
// androidMain
single<EmbeddingCache> {
EmbeddingCache(
fs = FileSystem.SYSTEM,
root = "${androidContext().cacheDir.absolutePath}/confetti-embeddings".toPath(),
)
}
single<Embedder> {
ApiEmbedder(
provider = GoogleLLMClient(
apiKey = BuildKonfig.GEMINI_API_KEY,
httpClientFactory = KtorKoogHttpClient.Factory(),
),
model = GoogleModels.Embeddings.GeminiEmbedding001,
)
}
1
2
3
4
5
6
7
8
9
10
11
12
// iosMain
embeddingCache()?.let { cache -> single<EmbeddingCache> { cache } }
@OptIn(ExperimentalForeignApi::class)
private fun embeddingCache(): EmbeddingCache? {
val url = NSFileManager.defaultManager.URLsForDirectory(
directory = NSCachesDirectory,
inDomains = NSUserDomainMask,
).firstOrNull() as? NSURL ?: return null
val path = url.path ?: return null
return EmbeddingCache(FileSystem.SYSTEM, "$path/confetti-embeddings".toPath())
}
Exposing it as a tool
The last step is to wire the index up as a Koog tool so the agent can call into it. We add a SearchSessionsTool alongside the existing GetSessionsTool, and use the tool description (and the agent system prompt) to help the model pick the right one for the question.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
class SearchSessionsTool(
private val index: SessionEmbeddingIndex,
) : SimpleTool<SearchSessionsTool.Args>(
argsType = typeToken<Args>(),
name = "SearchSessionsTool",
description = "Semantic search over sessions. Returns sessions ranked by how close " +
"their title and description are in meaning to the given query, along with a " +
"similarity score in [-1, 1] (higher is more relevant). Use this for any topic " +
"or theme query, including single-word topics like \"AI\", \"testing\", or " +
"\"UI\", since it surfaces related talks even when they use different words.",
) {
@Serializable
data class Args(
@property:LLMDescription("Natural-language description of the topic the user is interested in.")
val query: String,
@property:LLMDescription("Maximum number of sessions to return. Default 20.")
val topK: Int = 20,
)
override suspend fun execute(args: Args): String {
val matches = index.search(args.query, args.topK)
if (matches.isEmpty()) return "No matching sessions."
return matches.joinToString(separator = "\n\n") { scored ->
"Score: ${(scored.score * 1000).toInt() / 1000.0}\n${scored.session.summary()}"
}
}
}
We also tighten GetSessionsTool (previously a loose contains filter) into a whole-word regex match, and update its description so the model treats it as the literal-match fallback rather than the default. The system prompt then points the agent at SearchSessionsTool for topic-style queries and gives it some guidance on how to read the similarity scores.
1
2
3
4
5
6
7
8
9
10
11
Choosing between session tools:
- Default to SearchSessionsTool whenever the user asks about a topic,
theme, or area of interest, including single-word topics like "AI",
"testing", "UI" or "performance". Semantic search finds related talks
even when they use different vocabulary.
- Each SearchSessionsTool result includes a similarity score. Treat
scores above ~0.5 as strong matches; consider including borderline
results (down to ~0.3) when the user asks for "all" related talks.
- Only use GetSessionsTool when the user explicitly wants a verbatim
string match (e.g. "find talks with 'Kotlin Multiplatform' in the
title").
And finally we add the new tool (and the index it wraps) to the ToolRegistry used by ConferenceAgentProvider.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
val sessionIndex = SessionEmbeddingIndex(
repository = repository,
conference = conference,
embedder = embedder,
cache = embeddingCache,
)
val toolRegistry = ToolRegistry {
tool(GetSessionsTool(repository, conference))
tool(SearchSessionsTool(sessionIndex))
tool(GetSessionByIdTool(repository, conference))
tool(GetSpeakersTool(repository, conference))
tool(GetSpeakerByIdTool(repository, conference))
}
With this in place, the agent can now answer questions like “what UI related talks are on?” by pulling semantically related talks, while still being able to fall back to a literal title match when the user is being specific.
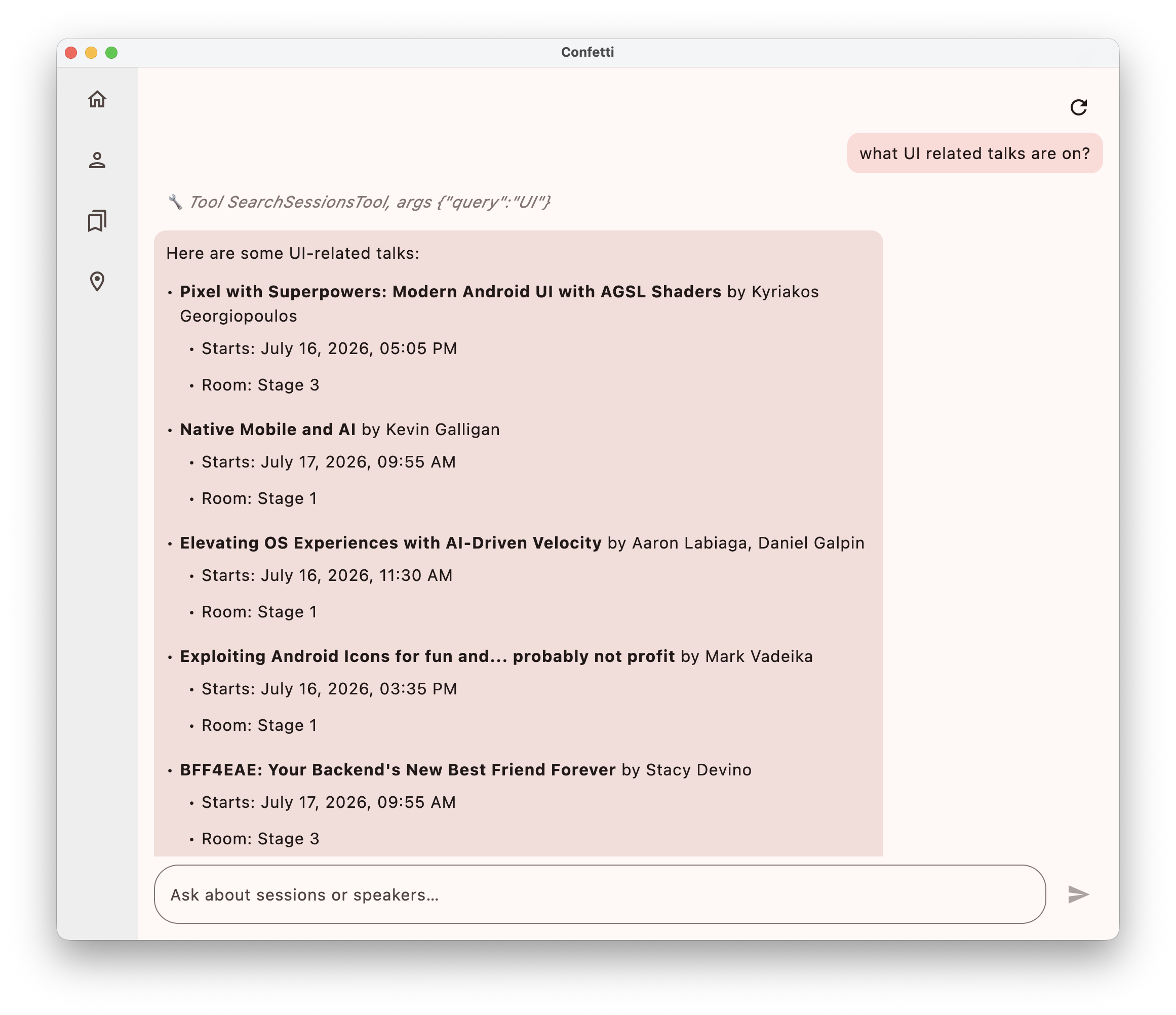
Featured in Kotlin Weekly Issue #513 and Android Weekly #729
Related tweet
Adding embeddings/RAG support to the Koog-based AI agent in Confetti https://t.co/wu7APfGa2r
— John O'Reilly (@joreilly) May 26, 2026
This is using @GeminiApp for the LLM and the embedding model so might as well use it to generate image for the article 😀